~続・不動産とファイナンス・賃貸物件入居者編(3)~「機械学習を使って東京23区のお買い得賃貸物件を探してみた」を千葉県で再度やってみる(予測編)
今回は、不動産賃貸物件の賃料予測シリーズの最終回です。
(分析のソースコードは最後に一括掲載します)
データクレンジングした千葉県の賃貸物件情報データセットを使って、予測に入っていきます。
その前に、データクレンジングについて補足があります。
スクレイピングの段階で物件の住所が抜け落ちていることに気づきましたので、後から付け足しました。
市ごとにデータを抽出していたため追加は問題なかったのですが、コードを参照される方はご注意ください。
毎度のことながら、こちらが参考記事です。
基礎分析
実は今回の記事は下の記事の続編でして、全体の外観は既に見ていました。
前回と今回の違いは、物件の構造や駐車場有無など新たに変数を追加した点です。
(スクレイピングにすごく時間がかかりました)
なお、今回も市別物件数等の基礎統計は出していますが、大きな違いはないため重複する内容は前回に譲ります。
https://blog.hatena.ne.jp/d_s/d-s.hatenablog.com/edit?entry=10257846132614731711
では、最初に今回使うデータセットを載せておきます。
df(38906,19)
はじめに、家賃と相関が高い変数を見ておきます。
家賃との相関係数が絶対値で0.5超のものを抽出してあります。

monthly_cost:家賃、area:専有面積、age:築年ですが、家賃と専有面積の相関が1番高そうです。
感覚的にもそうだろうなと思いますよね。予測の際に重要になりそうな変数です。
次は、建物構造をスクレイピングしてきているので家賃との対応を見ておきます。

やはり木造が・・・という結果になりました。
自分もアパート暮らしを経験したことがありますが、物件の構造は気にしていました。
鉄筋だの鉄骨だの細かくこだわっていませんでしたが、木造だけは「音が気になる」という先入観を持っていたので、当時選択肢にすら入れていなかったのを覚えています。
以下、変数ごとにヒストグラムを描いて分布を確認して、データが寄っていたら対数変換して正規分布に近くなるか確認して・・・と続いていくわけなのですが、長々としてしまいますのでこんな例を載せておきます。


最寄り駅までの距離ですが、これを対数変換すると


幾分か正規分布、線形に近づいたと思います。
今回はこのまま重回帰に進みますが、もっとぐりぐりと探索したいところではあります。その他処理については、コードに解説を。
(後で気づきましたが、元のデータセットで対数変換しようと思ったものを変換し忘れていました。orz)
次に予測に入っていきます。
今回もデータセットを学習:テストで8:2に分けて検証します。
学習データ:tarin(31111, 14)
テストデータ:test(7776, 14)
予測1 重回帰
まずは重回帰分析です。
コードを参照していただければと思いますが、カテゴリー変数はダミー化しています。
先に述べたように、今回Step関数(AIC最小化)で変数選択していますので、下の結果は変数選択後の結果です。
Intercept(切片)のEstimate(偏回帰係数)が51597ですので、解釈としては51597円をベースとして、加算減算し家賃が求まる式ができました。
例えば市で見ると、浦安の偏回帰係数が9991、千葉が-4705ですので、その物件が浦安であれば51597円+9991円、千葉であれば51597円-4705円といった具合で計算されていきます。
市を見ると、東京から遠ざかるにつれ係数が下がっていくのでこれは納得ですね。
area(専有面積)については、偏回帰係数が933と出ています。
1平米あたり933円という解釈になりますが、今回のデータセットの平米家賃単価(平均家賃÷平均専有面積)は2193円ですので、その差額が他の変数で説明されている部分と捉えられそうです。
今回の重回帰分析の決定係数は0.84なのでなかなか良い結果と言えるのではないでしょうか。
試しに、テストデータで予測を確認しておきます。

重回帰でそれなりに予測できていそうです。
こうなってくると、次のランダムフォレストでの結果も楽しみです。
予測2 ランダムフォレスト
比較しやすいように、先に結果を載せてしまいます。

さらに精度がよくなったようです。
実は今回、ランダムフォレストの学習時間短縮のために、学習データをさらに6割に削減したので不利なはずでした。
それなのにこの結果とは。。。改めてランダムフォレストの強力さを実感しました。
(テストデータは重回帰とまったく一緒です)
なお、今回のパラメータは例のごとくtuneRF関数でmtry(特徴量の数)を求めました。
mtryは8が最適のようです。

変数重要度は以下の通りアウトプットされました。
ランダムフォレストでは築年数、専有面積が重要な要因のようです。

以上、重回帰とランダムフォレストをざっとみてきましたが、ここで精度を比較しておきます。
RMSE(平均)という「平均化された誤差」という指標で比較したいと思うのですが、
上記の通り、重回帰:7095、ランダムフォレスト5133と、ランダムフォレストのほうがRMSEが小さい(誤差が相対的に低い)ので、ランダムフォレストのほうが良い結果を出すことができました。
予測3 お得物件を見つける
やっとここまでたどり着きました。
以下はランダムフォレストで予測した家賃をもとに、実際の家賃との差額からお得係数を算出してソートしたものです。
(お得係数:僕が勝手に考えた係数で、差分÷家賃共益費で算出)
| 物件 | 市 | 間取 | 面積 | 築年 | 駅 | 最寄駅距離 | 構造 | 家賃+共益費 | 予測家賃 | 差分 | お得係数 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 景中寮 | 流山市 | ワンルーム | 18.00 | 31 | 東武野田線 | 9 | 木造 | 12000 | 31058.24 | 19058.24 | 1.5881867 |
| カルフォルニアハウス江戸川台202号室 | 流山市 | 1K | 7.30 | 14 | 東武野田線 | 6 | 鉄筋コン | 20000 | 47337.43 | 27337.43 | 1.3668713 |
| カルフォルニアハウス江戸川台201号室 | 流山市 | 1K | 6.60 | 14 | 東武野田線 | 6 | 鉄筋コン | 20000 | 46878.56 | 26878.56 | 1.3439278 |
| カルフォルニアハウス江戸川台101号室 | 流山市 | 1K | 7.70 | 14 | 東武野田線 | 6 | 鉄筋コン | 20000 | 46210.84 | 26210.84 | 1.3105422 |
| JR総武線津田沼駅2階建築26年 | 船橋市 | 1K | 20.00 | 26 | JR総武線 | 15 | 木造 | 22000 | 47256.80 | 25256.80 | 1.1480366 |
| ヴィレッジダイドー | 千葉市 | 1LDK | 42.00 | 46 | 千葉都市モノレール | 25 | 鉄筋コン | 27000 | 57002.69 | 30002.69 | 1.1112108 |
| ビレッジハウス二和1号棟305号室 | 船橋市 | 1K | 45.36 | 57 | 新京成線 | 4 | 鉄筋コン | 34000 | 66637.96 | 32637.96 | 0.9599399 |
| アーバンハイム金丸 | 習志野市 | ワンルーム | 18.00 | 19 | 京成本線 | 6 | 木造 | 27000 | 48302.86 | 21302.86 | 0.7889947 |
| 大和田ハイツI-1 | 八千代市 | 1K | 20.00 | 50 | 京成本線 | 10 | 木造 | 19000 | 33909.16 | 14909.16 | 0.7846928 |
| ハイホーム田中305号室 | 市川市 | 1K | 19.80 | 48 | JR総武線快速 | 7 | 鉄筋コン | 31000 | 55022.72 | 24022.72 | 0.7749265 |
この中から、気になる物件を見てみます。
まず、お得度第一位の物件


おお、男子寮がランクインしてきました。
学生向けの物件でしょうか。ちょっと前提から外れる物件な気もしなくはないですが、破格の値段です。
寮なので、シェアハウスのごとく部屋以外は共同のようですが、写真で見る限り中は綺麗でした。
つぎは、個人的に目に留まった物件で、総武線市川駅徒歩7分です。
お得ランキングとしては10位です。築古なので年季が入っているようですが・・・


家賃共益費込みで31,000円!!!!!!!
築古ワンルームですが、東京の近さと、最寄り駅の近さを勘案するとすごくお得な物件ではないでしょうか?おまけに角部屋、鉄筋コンクリートです。
ちなみに、中の写真を見てみると・・・


築古だけとリフォームしてある感じで綺麗!!!
そしてお風呂が見当たらない!!!!!!!!!
なるほど、そういうことだったんですね笑
もしかしたら、お得度上位物件は、変数で考慮されていない特徴ある訳あり物件が並んでいるのかもしれません。笑
逆に言えば、一般的な物件は予測精度が良いのかもしれません。
風呂有り無し等、スクレイピングレベルで再度試すのは面倒ですが、今回の施行は面白いものとなりました。
次に
賃貸物件の賃料予測は無事行うことができましたが、次回は収益物件の値段の予測問題に入っていきます。収益物件の価格の妥当性を検証したいわけです。
実は、収益物件売買情報掲載サイトの「楽待」をスクレイピングして、既にデータセットを作成してあります。
楽待でも、今回の賃料予測に対応して千葉県の収益物件を取ってきていますので、収支予測を今回の結果をベースに行い、DCFベースの物件価格評価を目指します。
DCFをやるからには、割引率は収益物件の想定利回り(投資家が求める期待リターンとも言えるのか)の構造を重回帰等で割り出して算出してみたら面白いんじゃないかと考えています。
賃貸物件の賃料予測は、これにて終わりです。
本日のコード
~続・不動産とファイナンス・賃貸物件入居者編(2)~「機械学習を使って東京23区のお買い得賃貸物件を探してみた」を千葉県で再度やってみる(データクレンジング編)
今回は前回記事の続きで、SUUMOから取得してきたデータのクレンジングを行います。
なお、このテーマはshokosakaさんの記事が参考となっています。
参考記事ではPythonでデータクレンジング(前処理)を行っていますが、私はR で実施しています。
Pythonでも似たようなコードになると思うので、Pythonユーザーの方でも問題ないと思いますが、ご希望の方はコメントくださればPythonのコードも書いて追記します。
では、さっそく内容に入っていきます。
前回の記事でスクレイピングしてきたデータをクレンジングした結果を先に見ておきます。
以下のようになりました。
変数名は日本語をローマ字で充てたものと、簡単な英単語なので何かわかると思います。
補足をしておきますと以下の通りです。
area: 専有面積、age: 築年数、rout1: 最寄駅、distance: 最寄駅までの徒歩時間、
floor: その部屋が何階か、height: その物件は何階建か、car.dum: 駐車場有無、
free_rent: フリーレントの実施有無(期間は問わず)
以下が今回作成したRのコードです。
コードを解説しながら進めていこうと思ったのですが、コメントアウトを見ていただければそれなりにわかると思いますので、説明を省略してコードを載せてしまいます。
注意点としては、変数「distance(最寄り駅までの分数)」の取り扱いがあります。抽出した時点のデータセットでは徒歩とバスでの所要分数が入り混じっていました。
今回は、「最寄り駅まで徒歩で何分か」という基準で統一することにしたので、バス~分という場合は、バス~分に×4をして徒歩~分に置き換えています。
具体的には、バス10分であれば徒歩40分に置き換える。そんな感じです。
置き換えの根拠も載せてありますが、あくまで私なりの置き換え方法なので、何かアドバイスがある方はぜひ教えてください。
次回は、予測と物件リコメンドに入ります。
~続・不動産とファイナンス・賃貸物件入居者編(1)~「機械学習を使って東京23区のお買い得賃貸物件を探してみた」を千葉県で再度やってみる(Rでスクレイピング)
前回の記事で、千葉県の賃貸物件の賃料予測を実行するところまで行いました。
しかし、データ取得のところで課題がいくつかあったため、今回データ取得(スクレイピング)のやり直しです。
コードはまとめて最下部に記載します。
前回はshokosakaさんの参考記事にのっとりPythonでスクレイピングしましたが、予告通りRで完結させました。
データ取得
今回も、スクレイピング対象は下記のとおりです。
千葉県内で任意に選んだ市のSUUMO掲載賃貸物件データを取得
前回は白井市のデータも取得していましたが、物件数が少なかったため今回は対象から外します。
また、間取りは単身者向けを前提に、ワンルーム・1K・1DK・1LDKでフィルターをかけます。
その他フィルター条件は特にかけていません。
追加事項
前回と大きく違うところは、「物件の構造」「向き」「駐車場有無」等物件にかかる詳細情報を多数盛り込んだことです。
おさらいになりますが、下の写真の通り「詳細を見る」をクリックした先にある・・・

この画面、詳細情報にアクセスしてデータを取得してきています。


実はまだ松戸市のデータのみスクレイピング真っ最中なのですが、いかんせん物件に1件1件アクセスしてデータを取得する関係で、スクレイピングマナーとしてスリープ時間を設けるととてつもない時間がかかります。
それで、取得したデータは以下のようなものになります。
サンプルで3物件見てみます。
(変数名は適当でかっこ悪いですが。。。)
| 1 | 2 | 3 | |
|---|---|---|---|
| name | アスピリアベルフルール | Leaf(リーフ)103号室 | Leaf01030号室 |
| rent1 | 6.7 | 7.3 | 7.6 |
| rent2 | 4200 | 3800 | 3500 |
| shiki_rei | -/6.7 | -/7.3 | -/7.6 |
| hoshoukin | - | - | - |
| shikibiki_shoukyaku | - | - | - |
| layout | 1LDK | 1LDK | 1LDK |
| area | 44.67 | 44.13 | 44.13 |
| direction | 南西 | 南西 | 南西 |
| type | アパート | アパート | アパート |
| age | 6 | 6 | 6 |
| access1 | 新京成線/前原駅歩3分 | JR武蔵野線/船橋法典駅歩10分 | JR武蔵野線/船橋法典駅歩10分 |
| access2 | JR総武線/津田沼駅歩16分 | JR総武線/西船橋駅バス17分(バス停)上山町歩6分 | - |
| access3 | 京成本線/京成津田沼駅歩29分 | 東京メトロ東西線/西船橋駅バス17分(バス停)上山町歩6分 | - |
| detail_layout | 洋7.6LDK10.7 | 洋13LDK6.0 | 洋6LDK13.0 |
| construction | 木造 | 鉄骨 | 鉄骨 |
| floor_heigth | 1階/2階建 | 1階/2階建 | 1階/2階建 |
| car | 敷地内8640円 | 敷地内7560円 | 敷地内7560円 |
| jouken | 二人入居可 | 二人入居可/子供可/事務所利用不可 | 二人入居可 |
| kosuu | - | - | 8戸 |
ちゃんと、詳細情報が取れていますね。
あとは、これの前処理をしていって、再度基礎分析を行ってから予測に入っていきます。
本日のコード
urlは適宜打ち換えて試してみてください。
時間がかなりかかるので、小規模で試してみると良いかもしれません。
また、スクレイピングの途中http Error500、http Error400に見舞われることがありましたが、気にせず再度実行して情報を取ってきています。
更に、データ取得中にあるページでHTMLの構造が変わる?のか、2パターンのHTMLを考慮に入れる必要があることに気づきました。
おそらくPythonで欠損になった物件はこれが原因かもしれません。
ですが、根本はよくわかっていません。
原因、回避の仕方等わかる方がいらっしゃいましたらご教授下さい。
(スクレイピングは初心者のためハードコーディングです)
Rの【woeBinning】パッケージ がとても便利
分類問題をロジスティック回帰で予測しようと思ったらこのパッケージが便利そうです。
説明変数をWOE(Weight ou Evidence)ベースでビン化してIV(Information Value)
を算出してくれます。
「WOE」というよりクレジットスコアリングモデルの説明ですが、以下が参考になると思います。
https://www.worldprogramming.com/jp/blog/credit_scoring_pt5
説明変数のビン化(クラス化)についてはやり方がたくさんあるのでしょうが、春に受けたSASのクレジットリスクセミナーでもWOEについて時間を割いて解説されていました。
PythonでもWOEベースのビン化パッケージがあるのですが、Rもpythonも日本語で解説しているページがあまり見当たらないので紹介しておきます。
組み込みのGerman Creditデータセットを使用します。
Good/Badで結果および20の変数がついた1000行21列のデータフレームです。


実行すると、IVベースでの変数ランキングと、各変数ごとの変数プロットが出てきます。
変数分出てくるので、個別変数としてはduration in monthだけ載せておきます。
このBinning関数には渡せるパラメーターまだがいくつかあって、
stop.limit:ビン化により減少するIVの減少幅にリミットを設ける
min.perc.total:各ビンに入る目的変数の数の割合に下限を設ける
など柔軟にチューニングできそうです。
その他はHelpをご参照ください。
duration in monthは以下の通りビン化されています。
このdurationですが、binning関数にかける前のヒストグラムはこんな感じです。

近々、KaggleでみつけたHumanResourceAnalytics(会社をやめる人を予測する)データセットで、このビン化モジュールで前処理、ロジスティック回帰で予測を実施したいと思います。
その際に詳しく解説します。
~不動産とファイナンス・賃貸物件入居者編(2)~「機械学習を使って東京23区のお買い得賃貸物件を探してみた」を千葉県でやってみる
今回は前回の続きをやっていきます。
引き続き参考はこちらです。
参考のままですが、コードは追記しておきました。
では、まず前回見ていなかった築年数から見ていきます。

市川、浦安という東京(江戸川区)の隣接地域の築年数が高く、流山・鎌ヶ谷築年数が低いという結果が出ました。
流山、鎌ヶ谷については近年開発されている地域なので納得感がありますが、千葉は意外でした。
よくよく考えると、物件情報が掲載されている時点で、空室・または退去見込みの物件が掲載されているわけです。
よって、市川・浦安等の東京へのアクセスが良いエリアは、築浅物件ほど埋まっているのかもしれません。
「年数の経った物件が残りやすい→掲載物件ベースでは築年数が高く出やすい」という流れがあるのでしょうか?
こんな感じで物件掲載情報での集計だとバイアスがありそうなので、解釈には注意が必要だと思います。
予測
ここからが一番ワクワクします。
はじめに結論ですが、まずまず予測できたと感じるものの。。。
データセット内で、物件名と物件内容が一致していないものを多数見つけました!!
前回の分析中で、欠損を含むデータをドロップして気がかりで・・・と話しましたが、やはり嫌な予感が的中しました。
どうやら、スクレイピングの最中に何らかの原因で物件名と物件の内容にズレが起きていたようです。
物件内容自体は間違い無いと思うのですが、やはりやり直した方が良さそうです。
ということで、スクレイピングするところからやり直すこととします。
とは言ってもせっかくなので、一応の結果は挙げておきます。参考程度ということで。
以下ランダムフォレストの結果です。

パラメーターは、tuneRF関数でグリッドサーチしました。個々の決定木を作成する際に使用する特徴量の数「mtry」を求めた結果、6となりましたので、mtry=6でモデルを作成しました。
急速に収束していく様子がわかります。
次にランダムフォレストで学習した結果の変数(特徴量)の重要度を見てみます。

other_cost(敷金、礼金、保証金等)とarea(専有面積)、age(築年数)の重要度が高いことがわかります。以降、最寄駅、市、間取り1LDK、階、最寄り駅までの距離、間取り1K・・・と続きます。
間取りはダミー化してしまっているので不利な気もしますが、全体的に納得できるような腑に落ちない何かがあるような。。。
なお、RandomForestの特徴量の重要度算出について以下の記事が参考になります。
Random Forestで計算できる特徴量の重要度 - なにメモ
つづいて、予測の結果です。

データセット全体を、学習用:テスト用に8:2に分けて検証を行っています。
赤線のテストデータに対し、ランダムフォレストの結果が青ですので、それなりに予測できていそうですが、先に述べたようにデータセットに留意が必要です。
物件名は一応伏せてありますが、アウトプットの中ざっと見た中で気になった物件を一つ挙げてみます。

どうでしょうか?
こちらの物件は築古の1Kですが、津田沼駅徒歩7分の立地で、リフォームしてあるようです。
敷金礼金なしで、管理費共益費込41,000円は安いのでないでしょうか。
再チャレンジが必要になりましたが、一連のアウトプットを経て勉強になりました。
まとめ
今回の分析を通じて、どうしても追加したい思った変数がありました。
物件の構造です。
特徴量の重要度を見て何か腑に落ちない気がしたのは、まだ追加したいと思う変数が複数あったからです。
木造か軽鉄か、または鉄筋コンクリートなのかって物件選びで大事なポイントですよね。
また、物件の方角や駐車場有無なんかもあった方がより予測精度が上がるかもしれません。
総戸数がわかれば、その物件の入居率も変数として投入できます。
ということで、改めてsuumoを見てみます。
そういえば、今回「詳細を見る」の画面を気にもしていませんでした。
スクレイピングしてきたのは、この一覧画面で得られる情報に限定されていたわけですので、「詳細を見る」の中を見てみます。
あるじゃないですか!!
物件の向きから構造まで、そうそうこれが欲しかったんです。
実行時間としては相当な時間を覚悟しますが、物件詳細をループで処理していけば何とかなる気がしてきました。
よ~し、どうせスクレイピングし直すなら全部入れてしまえ!!
ということで、全項目取得します。
前回、Rでのスクレイピングを途中で断念してしまったので、あえて苦しみますがRでやり直そうと思います。
(Pythonに逃げるかもしれませんが、少しでもRに貢献したく。。。)
まだ途中ですが、ざっとこんな感じのデータフレームができそうです。

おおちゃくしてRstudioのキャプチャをのっけてしまい横が収まっていないですが、建物構造やその物件にかかる条件なんかも取得できています。
その他取得できる項目を全部変数化できればより面白くなりそうです。
まだ恥ずかしながらエラー地獄に陥っているためコードを公開できる状態ではありませんが、完成したら続編記事内で載せたいと思います。
スクレイピングはド素人ですが、Rで奮闘します。
やり出すと、何だかやり込みたくなってきました。
次回につづきます。
~不動産とファイナンス・賃貸物件入居者編(1)~「機械学習を使って東京23区のお買い得賃貸物件を探してみた」を千葉県でやってみる
今回は前々回の記事で触れた通り、以下のエントリを参考に千葉県のお買い得賃貸物件を分析して探してみます。
shokosakaさんのブログですが、大変勉強になりました。
このブログをなぞる形で進めてみます。
その前に、ブログを始めてわかったのですが、高校時代にサッカー部で共に汗を流したK君がこんな面白い記事を書いていたので合わせて紹介しておきます。
K君は僕と違い物理方面の科学者(FaceBookによるとナノサイエンス?)なわけですが、経済・ファイナンス界隈の人が一度は経験するラグランジュ未定乗数法を直感的なプロットで説明してくれています。彼はいつの間にかフランスの大学で研究をやっていてフランスからレスポンスしてくれました。
また、matplotlibでCDジャケットを作ってしまうという暴挙も見せています。
さて、本題に入ります。
賃貸物件情報の取得条件
まず初めに、例にならってsuumoから賃貸物件情報を取得してきます。
もちろん千葉県を対象にするのですが、さすがに全エリアを対象にするわけにはいきませんので、以下の市に絞ってデータを取得してきています。(東京に近いところから選択)
また、ある程度前提を絞りたいので、さらに単身者向け物件に限定します。
検索条件として、間取りを「ワンルーム、1K、1DK、1LDK」でフィルターしています。その他の条件は特に付与していません。
賃貸物件情報の取得
僕は前処理からRで完結したいと思ったのでrvestを使ってスクレイピングしてこようと思ったのですが、何やら途中うまくいかなくなったので結局pythonで処理しました。
今回はBeautifulSoup4を使ってスクレイピングしています。
結果、欠損やら何やらざっと処理した結果、最終的に28,445件の物件情報になりました。
データ取得面での前処理はざざっと終わらせましたが、正直欠損をドロップする時点で気がかりなこともありました。
いろいろ追求したいところですが、試行ですので先に進みます。
基礎統計
ここからが分析のスタートです。
実務では、先のデータ取得、データのクレンジング、基礎統計で外観を把握、問題あれば再度データのクレンジング・・・と途方もないループがあって一番時間がかかるところではあります。
まず、市別にSUMMO掲載物件数を見ていきます。

shokosakaさんの記事のまんまですが、言わずもがな人口の多い都市順に並んでいそうです。
では、物件数と人口でプロットして確かめます。
(人口は2015年)

おお、綺麗な回帰直線が引けました。
やはり都市人口と物件掲載数は強い相関があることがわかりますね。
習志野市だけ信頼区間から飛び出ていますが、物件の供給過剰なのでしょうか?
昨今、相続対策と消費税増税を謳ったアパート建築が流行ったので、築年数を分析すれば見えてくるのかもしれません。
さて、入居者としては一番の関心事である家賃を見ていきます。
家賃の中央値が高い順に並べます。

これは納得ですね。どうやら都心に近い順に並んでいそうです。
流山が3番目に来たのは 意外でしたが、つくばTX沿線の開発で新しい物件が多いのかもしれません。
以前、流山おおたかの森SCのTOHOシネマズによく映画を見に行きましたが、住環境としては文句のつけようのないような場所だと感じていました。
逆に、流山市の家賃の最低価格は相当安いので旧市街・新市街で相当な差があるのでしょう。
また、市川、千葉、松戸についてはどうやら変なデータが紛れ込んでいそうです。
単身向け物件にしては相当な値段の物件が見られますが、間取りの設定ミスか値段の設定ミスでしょう。
モデルを作成する際には注意しなければなりません。
次に、外れ値を除外して同様に見てみます。

先ほどよりだいぶ見やすくなりました。
白井市については、そもそも物件数が125件程度なのでなんとも言えませんが、流山市はレンジが広いですね。
そして今更気づきましたが、不覚にも柏市を入れるのを忘れていました。。。
(知らない方のために言いますと、柏市は柏レイソルのホームタウンで千葉県内でも人気のある都市です)
やっとここまできましたが、だいぶ遅い時間になってしまいました。
その他、基礎分析を一気に行ってしまいます。
Bar Chart(by Frequency)

グラフが小さくと申し訳ありませんが、要約すると
・間取り
1K→1LDK→ワンルーム?→1DK→その他
・最寄り駅
JR総武線(圧倒的)→東京メトロ東西線→JR常磐線→京成本線→新京成線→JR京葉線→その他
・最寄り駅徒歩(分)
10分→5分→7分→8分→3分→その他
(その他、築年数等の分析を行いたいところですが今日はここまでということで。)
念のため変数とその欠損割合を確認して今日は終わりにしたいと思います。

次回はいよいよモデルを作成して割安物件を探していきます。
※コード追記(こちらのブログのほぼまんまです)
機械学習を使って東京23区のお買い得賃貸物件を探してみた - データで見る世界
Rと効率的フロンティアとCAPM(2)
前回の続きです。
早速効率的フロンティアを描いてみます。
これを実行すると以下のプロットが出ます。

一応ですが出ました。
3つの株式の組み合わせで得られるリスク、期待リターンが色付きの箇所になります。
これに、銘柄を限定せず全銘柄で効率的フロンティアを作りCAPM(資本資産価格)というものを組み合わせると無リスク資産(国債等、日本の現状では現預金と言い換えても?)を加えた戦略が得られます。
今回は例が悪かったので他から図を拝借してきますが以下のような感じです。
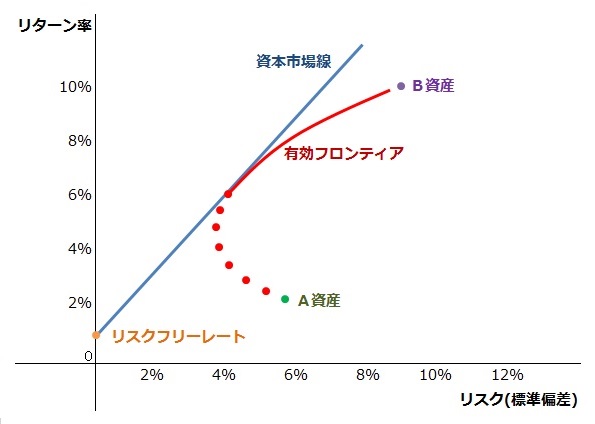
参照:http://words.equity-investment.info/portfolio.theory.html
効率的(有効)フロンティアのカーブが最小になる点を最小分散ポートフォリオ、資本市場線との接点を市場ポートフォリオと言います。
この市場ポートフォリオの正体こそが厳しい厳しい仮定の下得られたCAPMでして、
すべての投資家はこの市場ポートフォリオと無リスク資産を持つとしています。
市場ポートフォリオは、市場の関連情報すべてを折り込んでいるため、投資家は市場ポートフォリオを保有することで最適なポートフォリオを保持できるというものです。
これについてはもちろんいろんな意見がありCAPMも拡張されたりするわけです。
まとめ
長くなりましたが、これまでやってきた流れを乱暴な言い方で締めくくると、
「現金とTOPIX上場投信で資産配分考えておけばOK!!!!!!」と言えるのでしょうか。
あくまで理論的な話ですが。
次回以降は、前回冒頭あげたような身近なネタで分析していきます。