Shiny Tips / dygraphsパッケージ
RのShinyパッケージのTipsです。たまに更新していきたいと思います。
以下は、私が日ごろよく見るサイトです。
Shinyの情報は英語のサイトではたくさん出るのですが、日本語で読める情報ソースはそう多くないので大変参考になります。
www.randpy.tokyo
dygraphsパッケージ
dygraphsパッケージは、JavaScriptのチャート作成ライブラリーへのRインターフェースです。
時系列データのビジュアル化にとてもおすすめです。
主な機能としては、
などがあります。
インストールは以下のコマンドで。
install.packages("dygraphs")
サンプル
今回は、quantmodパッケージに入っているサンプルを使って、dygraphによる図とRawデータを出力しました。
コードは最後にまとめて載せます。

Tips
Rawデータを出力しておいたのには理由があって、ちょっとした細工をしています。
下図では、レンジセレクターの範囲を2月に絞っていますが、連動してRawデータも同範囲だけ表示されるようにしています。
時系列データのグラフ化は大変便利ですが、気になる点をRawデータで直接確認したい場面が多々あると思います。
そんな時に役立つと思います。

ui
library(shiny) library(shinydashboard) library(dygraphs) library(quantmod) library(xts) library(zoo) library(DT) dashboardPage( dashboardHeader(title = 'dygraphs sample'), dashboardSidebar( sidebarMenu( menuItem("dygraphs", icon=icon("line-chart"), tabName = 'tab_dygraphs') ) ), dashboardBody( tabItems( tabItem( "tab_dygraphs", box(dygraphOutput('res_dygraphs'),width = 12), fluidRow( shinydashboard::box( title = "dygraphs", width = 12, solidHeader = TRUE, collapsible = TRUE, status = "primary", DT::dataTableOutput('sample_df') ) ) ) ) ) )
server
shinyServer(function(input, output) { df <- reactive({ data(sample_matrix) df <- as.xts(sample_matrix) return(df) }) server_var <- reactiveValues() observeEvent(input$res_dygraphs_date_window, { server_var$v1 <- input$res_dygraphs_date_window[[1]] server_var$v2 <- input$res_dygraphs_date_window[[2]] } ) output$res_dygraphs <- renderDygraph({ dygraph(df(), main = "SampleTimeSeries") %>% dyAxis("y", label = "y") %>% dyRangeSelector(height = 20, strokeColor = "red") %>% dyCrosshair(direction = "vertical") %>% dyHighlight(highlightCircleSize = 5, highlightSeriesBackgroundAlpha = 0.2, hideOnMouseOut = T) }) output$sample_df <- DT::renderDataTable({ df <- df() range <- paste(as.Date.character(server_var$v1), "::", as.Date.character(server_var$v2), sep = "") df <- df[range] as.data.frame(df) }, filter = 'top', extensions = c('ColReorder', 'FixedColumns', 'Buttons'), options = list(colReorder = TRUE, scrollY = 650, scrollX = TRUE, pageLength = 100, fixedColumns = TRUE, searchHighlight = TRUE, buttons = c('copy', 'csv', 'excel', 'pdf', 'print'), dom = 'Bfrtip' ) ) })
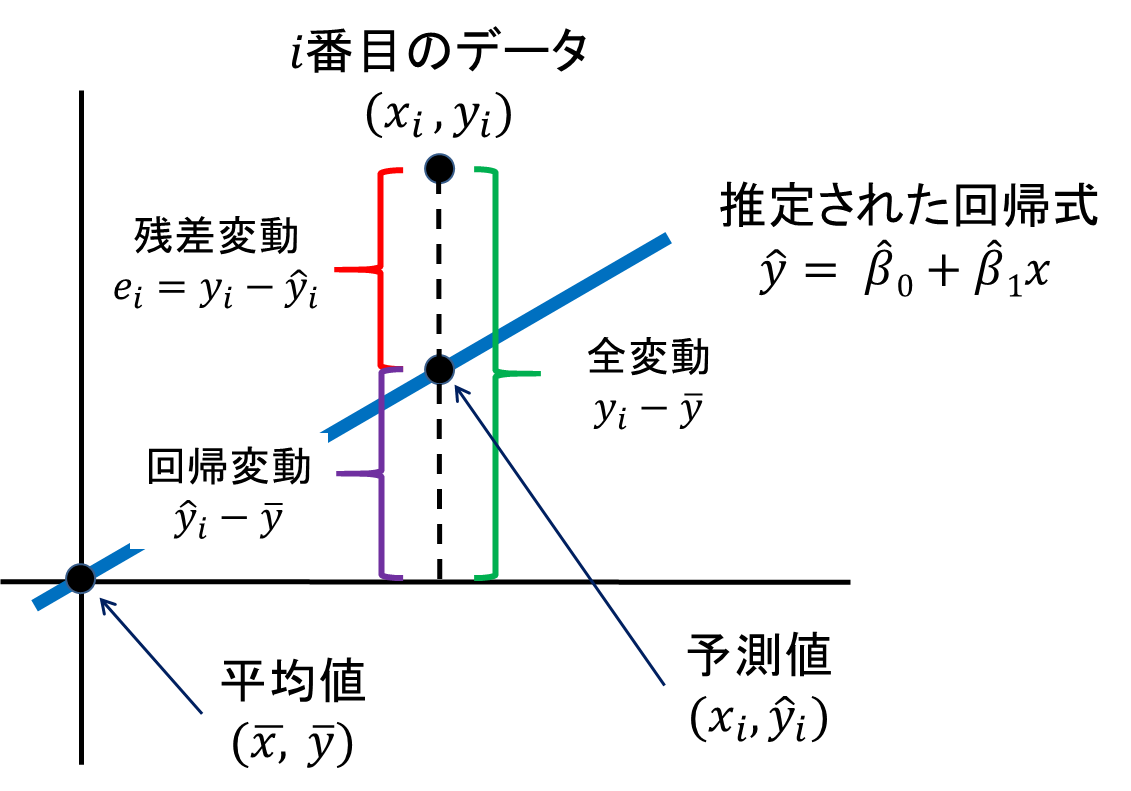
決定係数の導出をおさらい
備忘的にメモ。
平方和の分解
回帰直線を用いるとき、応答変数(目的変数)の変動の大きさを表す平方和
は、回帰による平方和
と残差平方和
の和
の形に分解できる。
観測値の平方和の式を変形すると
となる。
ここで、右辺第3項は予測値と残差の偏差積和を表すが、予測値と残差の相関係数が0であるため、この項は0。
また、第1項と第2項を入れ替え、
と観測値の平方和
は2つの平方和の和の形に分解できる。
ここで、右辺の第1項は回帰による平方和 (RはRegressionを指す)、第2項は残差平方和
と呼ぶ。
決定係数
上記、平方和の分解のうち、の平方和の中の回帰による平方和の割合
を決定係数、又は寄与率と呼ぶ。
理解しやすいように以下にまとめると、
- :応答変数yの変動の大きさを表す
- :回帰直線によって説明される部分
- :回帰直線によって説明されない部分
となる。
下図は統計Webより引用ですが、直感的に理解する上で非常に参考になります。このサイト自体解説も分かりやすいです。
Translation
今回は最近の取り組みを紹介します。
Software Carpentryという、研究者(リサーチャー)向けにRやPythonいったプラグラミング言語による分析スキルを教えているボランティアの日本語化プロジェクトにアサインしています。
RやPythonによる分析の仕方を中心に様々なレッスンが無料で公開されており、誰でも簡単に学ぶことができます。
きっかけは、Tokyo.RというR言語のコミュ二ティで「Software Carpentryの日本語化プロジェクトを始めたい」というニュージーランド人のトムのプレゼンを聞いて、ツイッターでプレゼンについて呟いていたら誘われたことでした。
英語なんて自信ないくせに、何を血迷ったかjoinしたい!っと返信して参加してしまいました。
早速プロジェクトが走り出して作業を進めていますが、勉強になることばかりで、参加してよかったなと思っています。
(git hubでプロジェクトを進めているので、git hubに入門するきっかけにもなりました。)
そして最後に毎度のごとく話が変わりますが、お題をTranslationとしたからか、"Lost in Translation"という東京が舞台の映画をふと思い出しました。
![ロスト・イン・トランスレーション [DVD]](https://images-fe.ssl-images-amazon.com/images/I/51J0ZKT0P9L._SL160_.jpg "ロスト・イン・トランスレーション [DVD]")
この映画、とても好きなので何回も観ているのですが、サントラで使われているMy bloody valentineというバンドの「sometimes」という曲が最高に好きです。
日本に縁もゆかりもなく、ただただ日本に来ることになった「外国人」の視点が描かれていて、その異邦人(外国人)が"Tokyo"のエネルギーに呑まれながら表現するストーリーがなんとも言えない孤独感とノスタルジックな雰囲気を出しています。そこで例のサントラがマッチして、病み付きになります。
ちょっと無理やりですが、モデリング実務の観点でいうと"Lost in Translation"になるのは避けたいですね。
状態空間モデルの簡単な備忘とAIのイメージ
最近は業務で時系列分析の比重が高まりつつあったため、いくつか時系列分析(特に状態空間モデル)の書籍を読んでいました。
基本的な計量経済学系の時系列モデルは学んだことがありますが(キレイに忘れてましたが。。。)、今回の業務の目的に合わせて状態空間モデルを一から勉強しています。
今回は特にプログラムは動かしませんが、概念的な話を備忘を兼ねてまとめておきます。
以下に、読んだ書籍を3冊挙げておきます。

時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装
- 作者: 馬場真哉
- 出版社/メーカー: プレアデス出版
- 発売日: 2018/02/14
- メディア: 単行本
- この商品を含むブログ (3件) を見る
ボックス・ジェンキンス法の解説にページを割いている分状態空間モデルの解説は多くないですが、基本的な時系列分析から状態空間モデルまで網羅できます。時系列分析を基礎からしっかりと学べ、応用への橋渡しをしてくれるという意味では他に類書がないのでは?とも思います。
読みやすい文章とわかりやすい解説で理解が深まりました。
なお、著者のHP(https://logics-of-blue.com/)も大変参考になるので合わせて参考にさせて頂いています。
")
カルマンフィルタ ―Rを使った時系列予測と状態空間モデル― (統計学One Point 2)
- 作者: 野村俊一
- 出版社/メーカー: 共立出版
- 発売日: 2016/09/08
- メディア: 単行本
- この商品を含むブログを見る
記載されているRのコードは、一貫してKFASパッケージを用いて記載されている為、KFASパッケージの解説本としても秀逸だと思います。
先の書籍とは違い、非線形非ガウス状態空間モデルの例として、フィルタリング系アルゴリズムの粒子フィルタが紹介されています。
正直理解がまだまだなのですが、理解を深めていきたいと思います。
")
予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで (KS理工学専門書)
- 作者: 樋口知之
- 出版社/メーカー: 講談社
- 発売日: 2011/04/07
- メディア: 単行本(ソフトカバー)
- 購入: 9人 クリック: 180回
- この商品を含むブログ (12件) を見る
最近買った本でまだ読み途中なのですが、ネット上の書評が良いのでkindleで買いました。この手の学術書としては珍しく?、平易な文章と身近な事例設定で解説が進んでいきます。第一章から「居酒屋の売上高の予測」の例で入っていくため、イメージがしやすいです。
また、モデルの解説はもとより「第一章 予測とは何かを考える」の1.1.2時系列データのところの著者のまとめが、「分析心得」のようにも思えバイブルになりそうです。
後ほど紹介します。
番外編
")
経済・ファイナンスデータの計量時系列分析 (統計ライブラリー)
- 作者: 沖本竜義
- 出版社/メーカー: 朝倉書店
- 発売日: 2010/02/01
- メディア: 単行本
- 購入: 4人 クリック: 101回
- この商品を含むブログ (6件) を見る
状態空間モデルとは何か
状態の時系列モデルと観測値
の生成モデルをそれぞれ
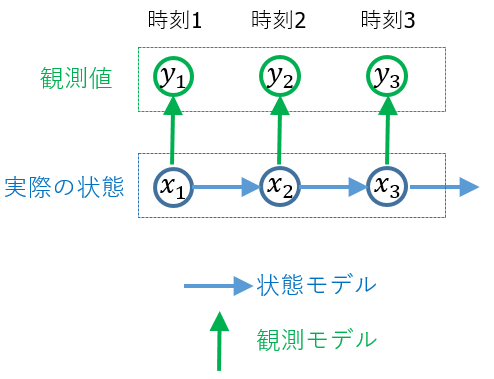
のように表現し、二つのモデルを合わせたものを状態空間モデルと呼びます。
状態空間モデル(状態空間表現)を使うことで「実際の状態を表すもの」と「観測できるもの」を区別して数式で表現することができます。
モチベーション
例えば、とあるレストランの日次売上推移を考えると、トレンドや自己回帰成分だけでなく、曜日(祝日)効果、イベント効果、天候など、売上の増減に関わる要因を分解することができます。
ボックス・ジェンキンス法の代表格である自己回帰モデル(ARモデル)では、上記のような要因を量的に把握できません。
(ARモデルは、自身の過去のデータの線形和+ノイズで表現される)
売上の変動に寄与する要因一つ一つについて、ドメイン知識のある人は経験的に知識を持っていると思いますが、それらが予測式に盛り込まれていないことは非効率だと言えます。
経験的知識の中には相当に不確実なものも含まれていますが、その不確実性も含めてデータに関わる知識を活用することがモデリングする上で重要だと思います。
もちろん、「データに語らせる」という視点も重要です。一方、「データドリブン一辺倒」にならないように注意が必要だと思います。
これらの点について、先程紹介した『予測にいかす統計モデリングの基本』の著者、樋口氏のまとめを以下に引用します。
分析業務にあたるうえで、いつも心に留めておこうと思います。
- 逆推論の機能:「いくつかの主たる要因が複雑にからみ合った結果がデータとなって現れている」との考えに基づき、データの分析は行われる。
- 結果の可読性:要因自体もデータ解析者が指定するほうが都合がよい。つまり、解析者の視点でもって要因を規定し、その要因でもってデータを説明することの妥当性を評価すれば、解析者のもつ視点自体を吟味することになる。この検討の結果は、データに対する解析者のイメージの修正を直接的に促進し、対象の深い理解につながる。
- 学習の効率性:未知のパラメータを決めるにはデータから学習するしかないが、ニューラルネットはパラメータの数が増えすぎると学習の効率が極端に悪くなる。理由としては、データの背後にあるさまざまな知識を直接的にパラメータ学習に利用せず、データを通した間接的利用にとどまっているからである。場合によっては全く利用していないことさえある。
状態空間モデルの例
引き続きレストランの日次売上推移を例にとり、ローカルレベルモデル(もっとも単純なモデルで、ランダムウォーク+ノイズモデル)に時変係数(広告効果)を導入したモデル式を考えます。
状態空間モデルでは、回帰係数が時間によって変化する「時変係数」のモデル構築が可能で、広告効果を例に考えると、時間経過とともにその効果が薄れていくことを表現することができます。
は
時点におけ外生変数(広告効果:広告宣伝費支出とする)の値で、
は
時点における回帰係数を指します。
AIのイメージ
最後に話は変わりますが、AI、機械学習について。
「誰でもわかるように分かりやすく説明して」とオーダーを受けることがあるのですが、自分の理解が不足していることに加え、AIのイメージが独り歩きしていて、 たいていうまく説明できません。 データを放り込めば「勝手に学習する。ほしいものが出てくる。」ようなイメージが感じられます。
そこで、概念的な話だけでなく、仕組みの話まで言及されるとどうしても専門用語を使いたくなるのですが、言い換えに苦労します。
ニューラルネットをイメージしてもらうのに、乱暴ですが「重回帰を多層にしたものをイメージして下さい」と言うと、場合によっては回帰の話から入らなければなりません。
また、広義のAIという意味でロジスティック回帰の話をすると、「それはAIではない。どこがAI?」という声が聞こえそうですが、層が一つのニューラルットの活性化関数をシグモイドにした場合、何が違うのか。。。(と心の中で思っているのはここだけの話)
そんな中、先程の樋口先生の引用文から、自分が歩んでいる方向性(解析者の持つ知識や予想といったデータへのイメージを直接的に数式を使って表現する)は間違っていないのだと勇気をもらいました。
AIC
今日は理論の話
最近、この本を読み直しています。
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
- 購入: 16人 クリック: 163回
- この商品を含むブログ (29件) を見る
第4章のAICについての記述で考えさせられたので、備忘を兼ねまとめます。
AICはモデル選択基準の一つです。
最尤推定したパラメーターの個数がkであるとき、以下の通り定義されます。
※は最大対数尤度
なぜAICでモデル選択してよいのか?
この本の第4章でのメインテーマですが、著者が指摘する「AICについてのいろいろな誤解」をしている”人たち”に自分が該当していることに気づき、はっとした思いになりました。
データ解析の中でモデル選択をしている人たちを観察していると、AICについてはいろいろな誤解をしていることがわかります。
まず、基本的な注意としては、AICは「あてはまりの良いモデル」を選ぶ基準ではないし、AICによって「真のモデル」が選ばれるわけでもない。
引用元 データ解析のための統計モデリング入門 4章6節
「あてはまりの良いモデル」や「真のモデル」ではなく、「良い予測をするモデル」を選ぶのがAICであると説明されています。
この「良い予測をするモデルを選ぶのがAIC」というところ、何も考えてないと見落としてしまいがちです。
でも、だとすればここで疑問が生まれるのですが、AIC最小化でモデル選択(変数増減法で変数選択等)を行ったとして、例えば選ばれた変数のp値が有意水準(5%)を超えている場合どう考えたら(対処したら)よいのでしょうか?
・・・結局のところ、明確な答えはないのだと思います。
少し脱線するかもしれませんが、p値至上主義の流れに対してはアメリカ統計学会が声明を発表しているようです。
下記のブログで見つけました。
統計の誤解と濫用や「p値至上主義」を憂慮しp値の6原則を発表したASAの声明に対する統計学徒の素人意見 - ★データ解析備忘録★
いずれにせよ、「係数の符号の向きが逆転している変数はないか」だとか「分析対象に対するドメイン知識と重ね合わせたときに違和感がないか」など試行錯誤的な取り組みが大事だということなのだと思います。
気づくと、「AIC最小化」や「p値(有意水準)」、「ROC,GINI」といった面々に気を取られすぎてしまうので、分析対象・ビジネス面のドメイン知識とのすり合わせを常々意識して”思考”を止めないようにしたいと思います。
結果、(相対的な)統計指標の改善に注力しすぎるより、むしろ、モデルを使う対象となる”ビジネス”そのものの運用や設計に目を向けたほうが良い場合もあるかもしれません。
脱線気味なのでまとめると、AICは「あてはまりの良いモデル」でなく「良い予測をするモデル」を選ぶ基準であるということ。改めてすごく考えさせられました。
Juliaを試す
Juliaについて
Juliaはプログラミング言語の一種です。
特徴を一言でいうと「処理が速い、わかりやすい」だそうです。
2009年から開発が始まった言語(ようするに開発途上)でバージョンも0系だったのですが、8月にバージョン1.0系がリリースされたとのことで試すことにしました。
日々RとPythonで業務を行ってい特段不自由もしていないのですが、やはり膨大な処理となると実行終了まで1日放置は当たり前で、挙句にミスに気づいたときは卒倒ものです。
実行時間が短くなれば、トライアンドエラーにもっとたくさんの時間を費やすことができるので生産性が上がります。
なのでJuliaには大いに期待です。
余談ですが、科学技術計算によく使われる言語の速度比較記事がありましたので、リンクを張っておきます。
言語自体の仕組みについては全然理解していないので、正直に数字を見て真に受けるしかないのですが、見るからには確かに爆速です。
処理の内容によっては差が無いものもあるようです。
Juliaのインストール
こちらの公式サイトよりダウンロードしました。
IDEはJupyter notebookを使用しています。
僕はPythonでJupyter notebookに慣れ親しんでいるので他は見ませんでしたが、JunoというATOMベースのIDEがメジャーなようです。
Jupyter notebookの設定は以下の通りで完了しました。
- Juliaのインストール
- REPLを立ち上げる
- import Pkg
- ] ←(パッケージモードになる)
- add IJulia
- バックスペース ←(パッケージモードから抜ける)
- using IJulia
- notebook()
Rのサンプルデータで 回帰を試す
今回は、RDatasetsからHousing Datasetで試します。

今回はサクッと回帰を行いたいだけなので、変数はPrice(価格)とLotSize(土地面積)に絞って見ていきます。
回帰する前に、プロットも試しておきます。
まずは散布図。

続いて、Priceについてヒストグラムを描いてみます。

回帰するにはちょっと前処理したい分布ですが、どんどん進みます。
回帰を実行します。

感想
ざっと触ってみた結果、導入部分としては入りやすそうな印象を受けました。
実際はもっと奥が深くJuliaの本領を発揮させる領域(コードの書き方)があると思いますが、Jupyterでさくさく実行できる点が敷居を下げている気がします。
これから発展していく言語だと思いますので、注目していこうと思います。
RESAS
最近興味を持ったこと。
RESASは、一言でいうと官民ビッグデータがいろいろと収納された可視化ツールです。地方創生に向けた施策の一つで、自治体が客観的なデータに基づく形で地域の現状や課題を把握できるようにすることを意図しているようです。
これまでにRESASの存在は知っていましたが、使ったこともなかったため勉強がてらいじってみました。
ちなみに、今回は「政策アイデアコンテスト」ということで、一つ自治体を選んでRESASを用いた分析と政策提言をパワポにまとめることがお題のようです。
一方で、RESASのAPIを絡めたアプリ開発コンテストたるものもあります。
さて、RESASの便利なところは、APIが公開されているところと、APIを使わなくてもそのままテーブルデータをダウンロードしてこれることです。
市区町村ごとにいろいろな項目をテーブルデータで引っ張て来ては結合、クレンジングを繰り返して一つのデータセットに仕上げましたので多変量解析の題材にしてみます。
僕が分析対象にした自治体は20・30代人口の社会減が顕著でしたので、自治体ごとの20・30代人口社会増減(人口比)を目的変数に設定して色々と分析を試行しました。
※社会増減は2010年→2015年の変化が最新のデータです
結果的には、20・30代人口社会増減の上位10%の自治体に1(フラグ)を立てて、それ以外を0に置き換えてロジスティック回帰を行いました。
※上位10%の自治体は、すべて社会増です
この手の分析だと重回帰だよねとなりそうですが。。。
連続値をわざわざ0と1に置き換える(情報量が失われる)ことに何の意味があるのか突っ込まれたら苦しいですが、目指したいのは「社会増減上位層」との比較を通じて弱みを見つけることと、スコアリングの手法を使って解釈しやすいモデルを作りたい。というそれだけです。
今回もRで分析を行いましたが、試行錯誤的にモデルを組んだので、とりあえず結果だけ。
今回選んだ変数とスコアカード、スコア分布はこんな感じです。
スコアについては、高いほうがターゲットに近い(確率が高い)ことを意味するようにしています。

選んだ変数を見ると、一人当たり農林水産費のように、増えれば増えるほどスコアが悪くなる等、いわゆる「地方度合」を表しているとも解釈できる変数も入っています。
この手の変数はコントロールできるようなものでもなさそうです。
今回は約1500の自治体に対し200近い説明変数がついたデータセットを作成しましたが、相関やIV、giniを見ながら50くらいの候補変数に絞ったうえで試行錯誤的に変数選択を行いました。
変数の後ろについている「2011」や「2012」といった数字は、その変数の時系列を表します。目的変数は、2010→2015年の20・30代人口社会増減でしたので、できるだけ古い時系列の説明変数で投入しています。
2015年の直近である2014年の説明変数を投入して採用したとしても、人口の増減がその変数に影響を与えたのか、またはその逆か因果関係がわからなくなってしまうためです。
厳密にいえば2011年や2012年の変数でも完全な因果関係なんてわからないのですが。
因果関係を統計的に表現するのにベイジアンネットワークたる手法もあるようですが、そこら辺の知識は疎いため今回は試みていません。
ベイジアンネットワークの適用はこの手の分析で面白そうです。
また、予測が目的ではありませんが、一応モデルの精度を確認するためにデータセットを学習:検証(8:2)に分割しています。
作成したスコアカードを学習、検証データに適用すると、スコア分布はおおむね安定しているためモデルの精度は問題なさそうです。

参考までに、K-S値とROC曲線も確認しておきます。
K-Sの「Bad,Good」はそれぞれ「Target,non-Target」と読み替えてください。

長くなりましたが、このような流れで分析を続けた結果、僕が選んだ自治体は「創業比率」のスコアが他の自治体に比べて悪かったので、創業に関する施策を考えました。