状態空間モデルの簡単な備忘とAIのイメージ
最近は業務で時系列分析の比重が高まりつつあったため、いくつか時系列分析(特に状態空間モデル)の書籍を読んでいました。
基本的な計量経済学系の時系列モデルは学んだことがありますが(キレイに忘れてましたが。。。)、今回の業務の目的に合わせて状態空間モデルを一から勉強しています。
今回は特にプログラムは動かしませんが、概念的な話を備忘を兼ねてまとめておきます。
以下に、読んだ書籍を3冊挙げておきます。

時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装
- 作者: 馬場真哉
- 出版社/メーカー: プレアデス出版
- 発売日: 2018/02/14
- メディア: 単行本
- この商品を含むブログ (3件) を見る
ボックス・ジェンキンス法の解説にページを割いている分状態空間モデルの解説は多くないですが、基本的な時系列分析から状態空間モデルまで網羅できます。時系列分析を基礎からしっかりと学べ、応用への橋渡しをしてくれるという意味では他に類書がないのでは?とも思います。
読みやすい文章とわかりやすい解説で理解が深まりました。
なお、著者のHP(https://logics-of-blue.com/)も大変参考になるので合わせて参考にさせて頂いています。
")
カルマンフィルタ ―Rを使った時系列予測と状態空間モデル― (統計学One Point 2)
- 作者: 野村俊一
- 出版社/メーカー: 共立出版
- 発売日: 2016/09/08
- メディア: 単行本
- この商品を含むブログを見る
記載されているRのコードは、一貫してKFASパッケージを用いて記載されている為、KFASパッケージの解説本としても秀逸だと思います。
先の書籍とは違い、非線形非ガウス状態空間モデルの例として、フィルタリング系アルゴリズムの粒子フィルタが紹介されています。
正直理解がまだまだなのですが、理解を深めていきたいと思います。
")
予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで (KS理工学専門書)
- 作者: 樋口知之
- 出版社/メーカー: 講談社
- 発売日: 2011/04/07
- メディア: 単行本(ソフトカバー)
- 購入: 9人 クリック: 180回
- この商品を含むブログ (12件) を見る
最近買った本でまだ読み途中なのですが、ネット上の書評が良いのでkindleで買いました。この手の学術書としては珍しく?、平易な文章と身近な事例設定で解説が進んでいきます。第一章から「居酒屋の売上高の予測」の例で入っていくため、イメージがしやすいです。
また、モデルの解説はもとより「第一章 予測とは何かを考える」の1.1.2時系列データのところの著者のまとめが、「分析心得」のようにも思えバイブルになりそうです。
後ほど紹介します。
番外編
")
経済・ファイナンスデータの計量時系列分析 (統計ライブラリー)
- 作者: 沖本竜義
- 出版社/メーカー: 朝倉書店
- 発売日: 2010/02/01
- メディア: 単行本
- 購入: 4人 クリック: 101回
- この商品を含むブログ (6件) を見る
状態空間モデルとは何か
状態の時系列モデルと観測値
の生成モデルをそれぞれ
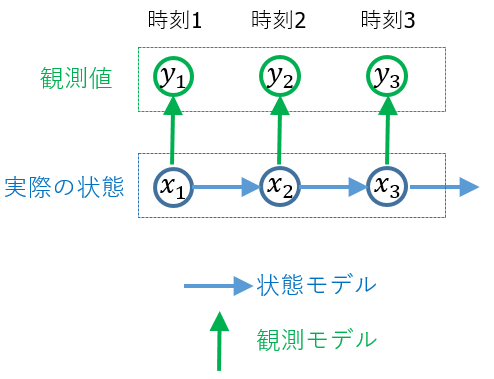
のように表現し、二つのモデルを合わせたものを状態空間モデルと呼びます。
状態空間モデル(状態空間表現)を使うことで「実際の状態を表すもの」と「観測できるもの」を区別して数式で表現することができます。
モチベーション
例えば、とあるレストランの日次売上推移を考えると、トレンドや自己回帰成分だけでなく、曜日(祝日)効果、イベント効果、天候など、売上の増減に関わる要因を分解することができます。
ボックス・ジェンキンス法の代表格である自己回帰モデル(ARモデル)では、上記のような要因を量的に把握できません。
(ARモデルは、自身の過去のデータの線形和+ノイズで表現される)
売上の変動に寄与する要因一つ一つについて、ドメイン知識のある人は経験的に知識を持っていると思いますが、それらが予測式に盛り込まれていないことは非効率だと言えます。
経験的知識の中には相当に不確実なものも含まれていますが、その不確実性も含めてデータに関わる知識を活用することがモデリングする上で重要だと思います。
もちろん、「データに語らせる」という視点も重要です。一方、「データドリブン一辺倒」にならないように注意が必要だと思います。
これらの点について、先程紹介した『予測にいかす統計モデリングの基本』の著者、樋口氏のまとめを以下に引用します。
分析業務にあたるうえで、いつも心に留めておこうと思います。
- 逆推論の機能:「いくつかの主たる要因が複雑にからみ合った結果がデータとなって現れている」との考えに基づき、データの分析は行われる。
- 結果の可読性:要因自体もデータ解析者が指定するほうが都合がよい。つまり、解析者の視点でもって要因を規定し、その要因でもってデータを説明することの妥当性を評価すれば、解析者のもつ視点自体を吟味することになる。この検討の結果は、データに対する解析者のイメージの修正を直接的に促進し、対象の深い理解につながる。
- 学習の効率性:未知のパラメータを決めるにはデータから学習するしかないが、ニューラルネットはパラメータの数が増えすぎると学習の効率が極端に悪くなる。理由としては、データの背後にあるさまざまな知識を直接的にパラメータ学習に利用せず、データを通した間接的利用にとどまっているからである。場合によっては全く利用していないことさえある。
状態空間モデルの例
引き続きレストランの日次売上推移を例にとり、ローカルレベルモデル(もっとも単純なモデルで、ランダムウォーク+ノイズモデル)に時変係数(広告効果)を導入したモデル式を考えます。
状態空間モデルでは、回帰係数が時間によって変化する「時変係数」のモデル構築が可能で、広告効果を例に考えると、時間経過とともにその効果が薄れていくことを表現することができます。
は
時点におけ外生変数(広告効果:広告宣伝費支出とする)の値で、
は
時点における回帰係数を指します。
AIのイメージ
最後に話は変わりますが、AI、機械学習について。
「誰でもわかるように分かりやすく説明して」とオーダーを受けることがあるのですが、自分の理解が不足していることに加え、AIのイメージが独り歩きしていて、 たいていうまく説明できません。 データを放り込めば「勝手に学習する。ほしいものが出てくる。」ようなイメージが感じられます。
そこで、概念的な話だけでなく、仕組みの話まで言及されるとどうしても専門用語を使いたくなるのですが、言い換えに苦労します。
ニューラルネットをイメージしてもらうのに、乱暴ですが「重回帰を多層にしたものをイメージして下さい」と言うと、場合によっては回帰の話から入らなければなりません。
また、広義のAIという意味でロジスティック回帰の話をすると、「それはAIではない。どこがAI?」という声が聞こえそうですが、層が一つのニューラルットの活性化関数をシグモイドにした場合、何が違うのか。。。(と心の中で思っているのはここだけの話)
そんな中、先程の樋口先生の引用文から、自分が歩んでいる方向性(解析者の持つ知識や予想といったデータへのイメージを直接的に数式を使って表現する)は間違っていないのだと勇気をもらいました。